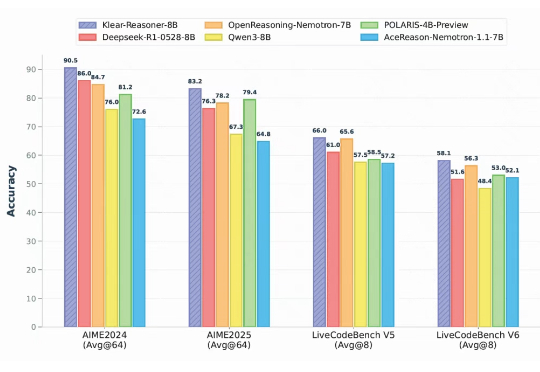
快手Klear-Reasoner登顶8B模型榜首,GPPO算法双效强化稳定性与探索能力!
快手Klear-Reasoner登顶8B模型榜首,GPPO算法双效强化稳定性与探索能力!在大语言模型的竞争中,数学与代码推理能力已经成为最硬核的“分水岭”。从 OpenAI 最早将 RLHF 引入大模型训练,到 DeepSeek 提出 GRPO 算法,我们见证了强化学习在推理模型领域的巨大潜力。
来自主题: AI技术研报
8476 点击 2025-08-22 17:23
 搜索
搜索
在大语言模型的竞争中,数学与代码推理能力已经成为最硬核的“分水岭”。从 OpenAI 最早将 RLHF 引入大模型训练,到 DeepSeek 提出 GRPO 算法,我们见证了强化学习在推理模型领域的巨大潜力。
软件+硬件的全链路国产 AI 体系来了? 这几天,不论国内国外,人们都在关注 DeepSeek 发布的 V3.1 新模型。
自从 GPT-5 发布后,DeepSeek 创始人梁文锋就成了 AI 圈最「忙」的人。
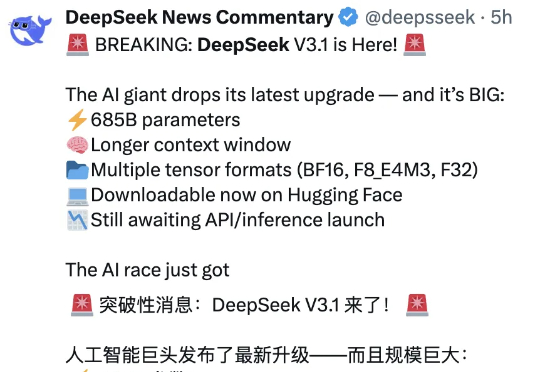
DeepSeek V3.1和V3相比,到底有什么不同?官方说的模模糊糊,就提到了上下文长度拓展至128K和支持多种张量格式,但别急,我们已经上手实测,为你奉上更多新鲜信息。

DeepSeek V3.1新版正式上线,上下文128k,编程实力碾压Claude 4 Opus,成本低至1美元。在昨晚,DeepSeek官方悄然上线了全新的V3.1版本,上下文长度拓展到128k。本次开源的V3.1模型拥有685B参数,支持多种精度格式,从BF16到FP8。

没等到Deepseek R2,DeepSeek悄悄更新了V 3.1。官方群放出的消息就提了一点,上下文长度拓展至128K。128K也是GPT-4o这一代模型的处理Token的长度。因此一开始,鲸哥以为从V3升级到V 3.1,以为是不大的升级,鲸哥体验下来还有惊喜。
AI能像科幻电影中的先知一样预测未来吗?一个名为「Prophet Arena」的全新基准测试,正通过预测真实世界事件来评估AI的「预言」能力。
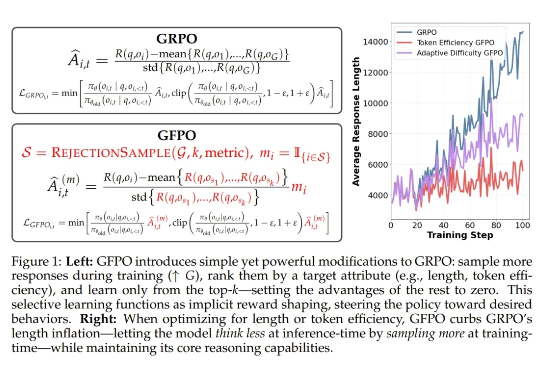
用过 DeepSeek-R1 等推理模型的人,大概都遇到过这种情况:一个稍微棘手的问题,模型像陷入沉思一样长篇大论地推下去,耗时耗算力,结果却未必靠谱。现在,我们或许有了解决方案。

GPT-5刚发布没多久,DeepSeek-R2就快来了,好热闹的8月份! DeepSeek预计将于8月发布其新一代旗舰模型DeepSeek-R2。
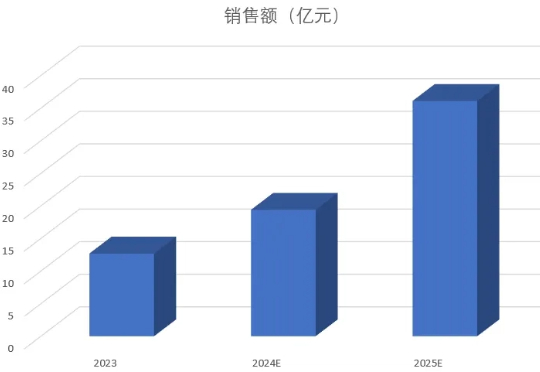
年初,DeepSeek 前脚带来模型在推理能力上的大幅提升,Manus 后脚就在全球范围内描绘了一幅通用 Agent 的蓝图。新的范本里,Agent 不再止步于答疑解惑的「镶边」角色,开始变得主动,拆解分析需求、调用工具、执行任务,最终解决问题……